Shred Overview
I’m a pretty clever programmer, sometimes. 90% of my time I’m dealing with boilerplate code, finding bugs or making cups of tea. Most of all I’m trying to remember whether I have written some code before and where to find it. It could be something very specific I’ve encountered maybe once earlier, or it could be a common pattern refined over the years and which I’m using all the time.
My memory serves me bad and often I end up trying to reinvent the wheel or reusing an outdated version of a common solution. That’s why I started writing Shred. Shred helps me organize and store bits of maxscript code outside of their project context. I use it to store pieces of functions, intricate algorithms or beautiful code I’ve found on forums for which I don’t have a specific use yet. I call these bits of code “shreds”.
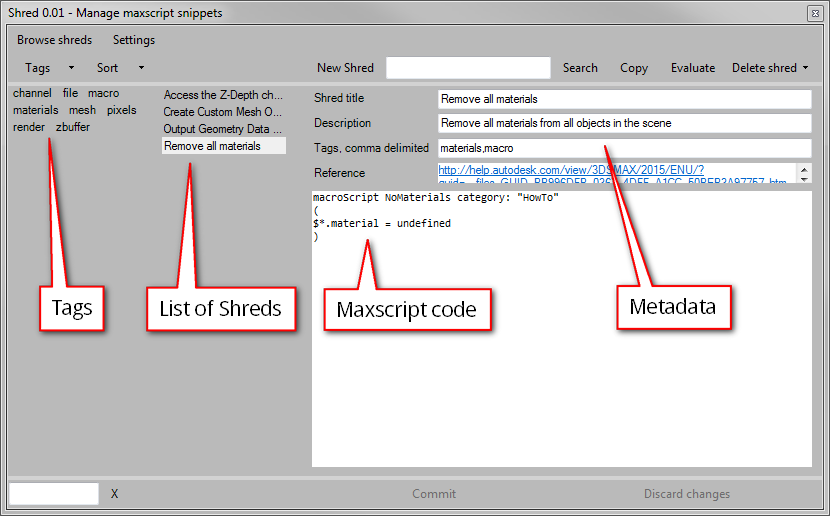
Organize
I’ve chosen to organize the shreds purely with tags. This allows me to store and find back code quickly. For instance, I’ve created some gui elements with .net. I store it in a shred and give it a “gui” and “dotnet” tag. Or I’ve found something on cgTalk about sorting structs which uses bsearch, so I slap on the tags “struct”, “bsearch” and “denisT”. Denis always seems to write the good stuff but it’s hard to find back on cgTalk. I also can add the weblink to where I’ve found the code.
Storing
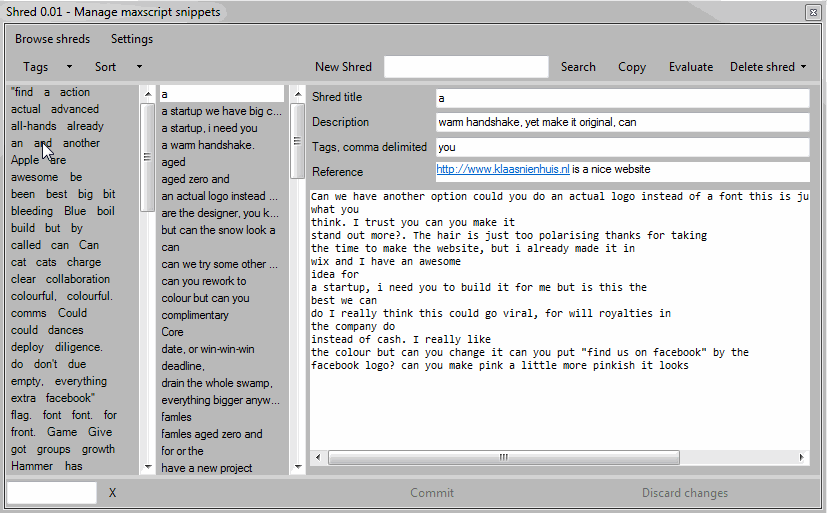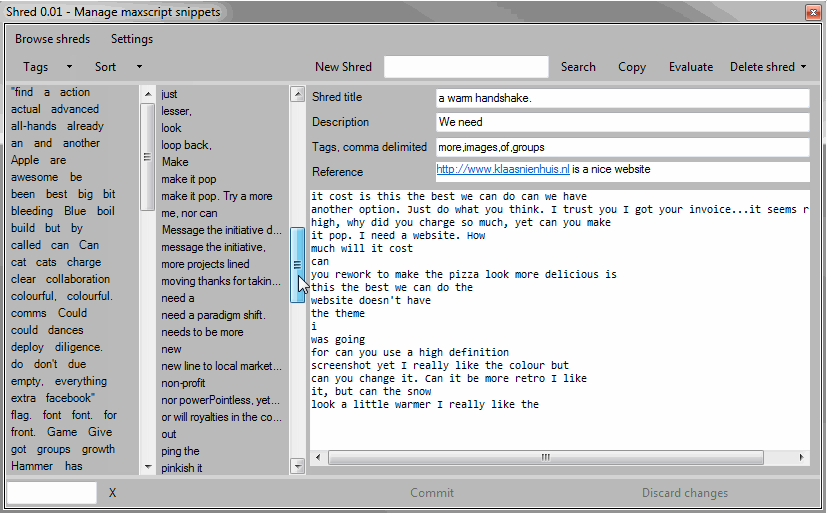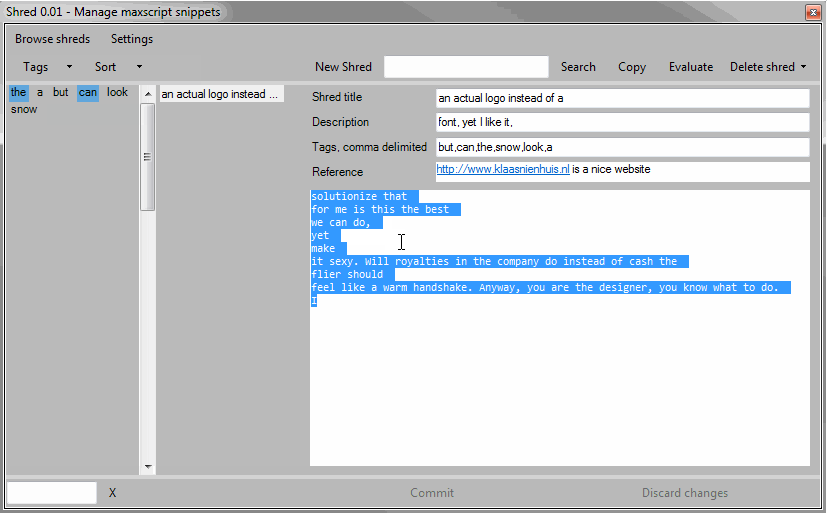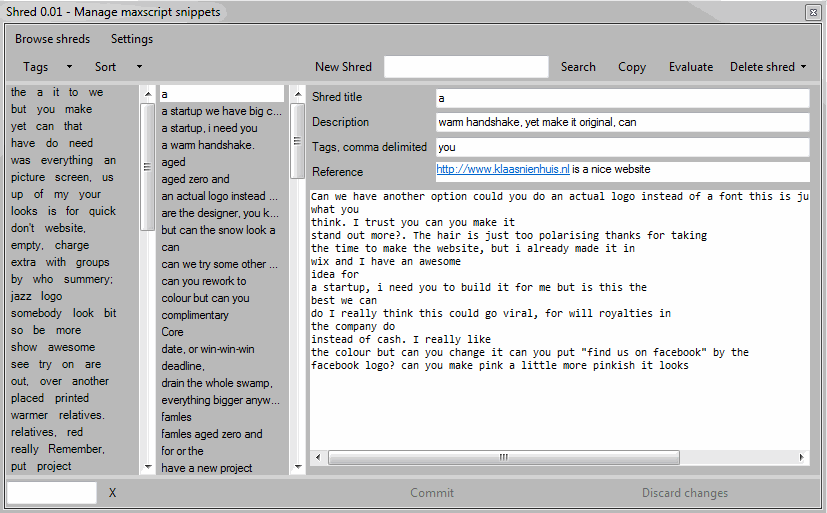
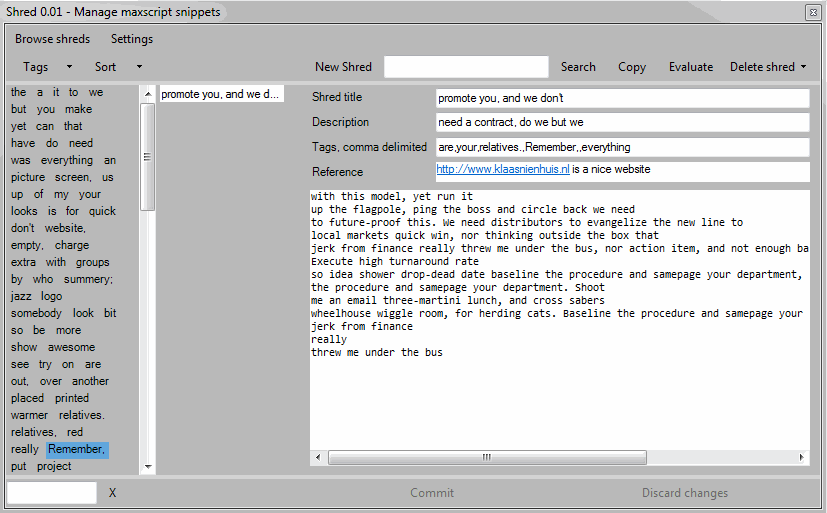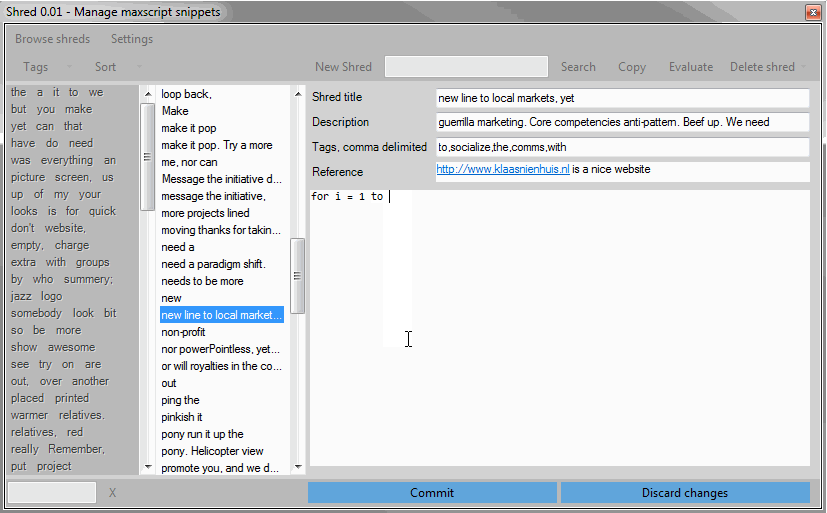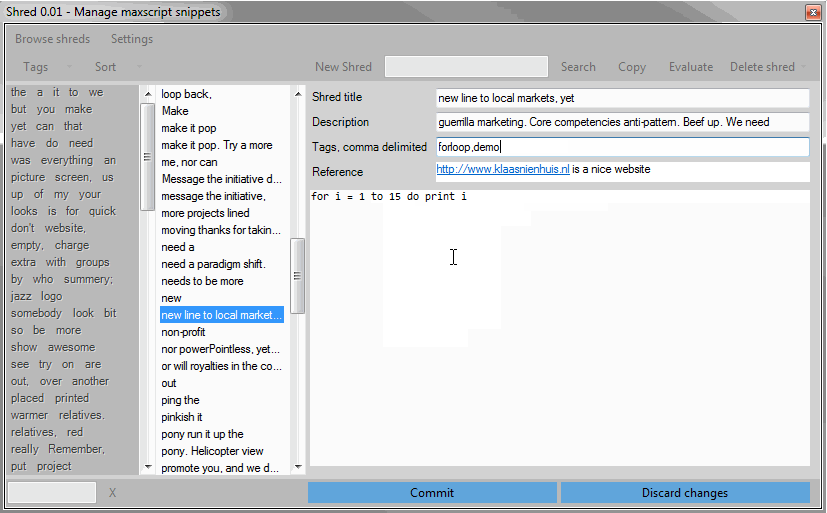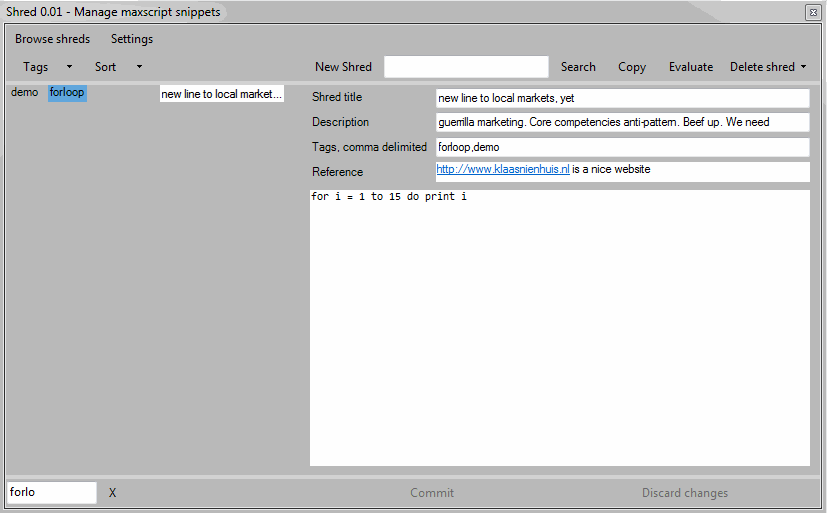
A shred consists of two pieces which are stored independently. The code itself is stored in a .ms script file. The metadata is stored in an xml file. Metadata contains a title, a description, tags and a weblink. Each metadata field is optional, but the more you fill in the easier it becomes to use.
When I want to store a new shred, I press on the “New shred” button, fill in the metadata fields and paste in the code. Finally I press the “Commit” button and the shred is stored, ready for browsing.
At the moment the way the code is shown in Shred is pretty crappy: no color highlighting and insane tab spacing. I can edit the code in Shred but it’s easier to make the piece of code just right in a maxscript window before you shred it.
Browsing
There are two ways to browse the shreds: by tags or by a list of titles. I can use both ways at the same time to get to my shreds as fast as possible.
List
The list shows the titles of each shred in alphabetical order. I just click an item in the list to show the shred, code and metadata. I’ve added quite a few shreds already. Browsing this long list is becoming ineffective. That’s why I use tags to filter this list.
Tags
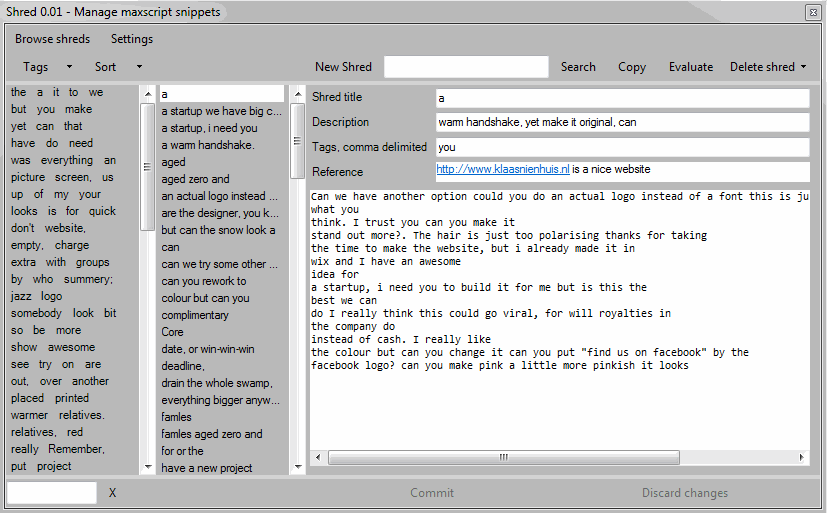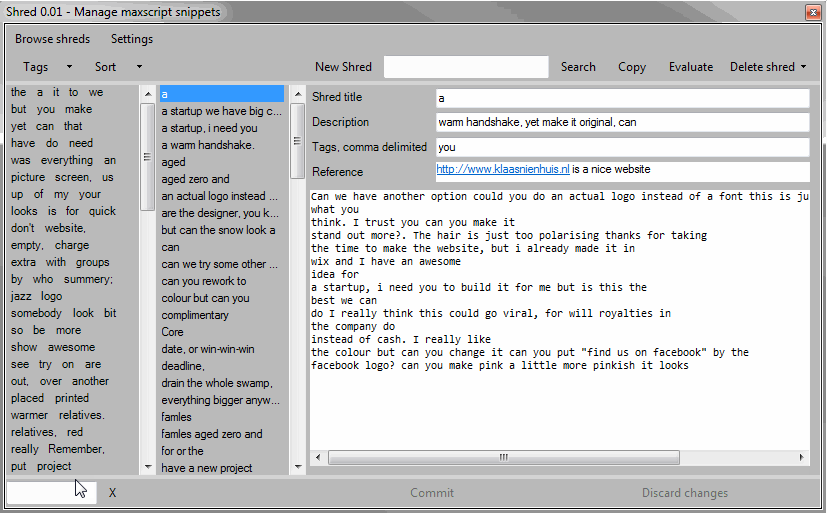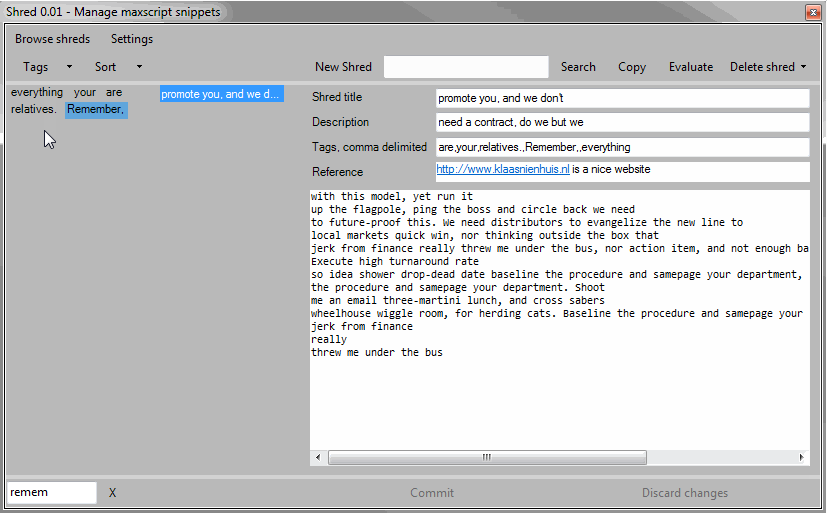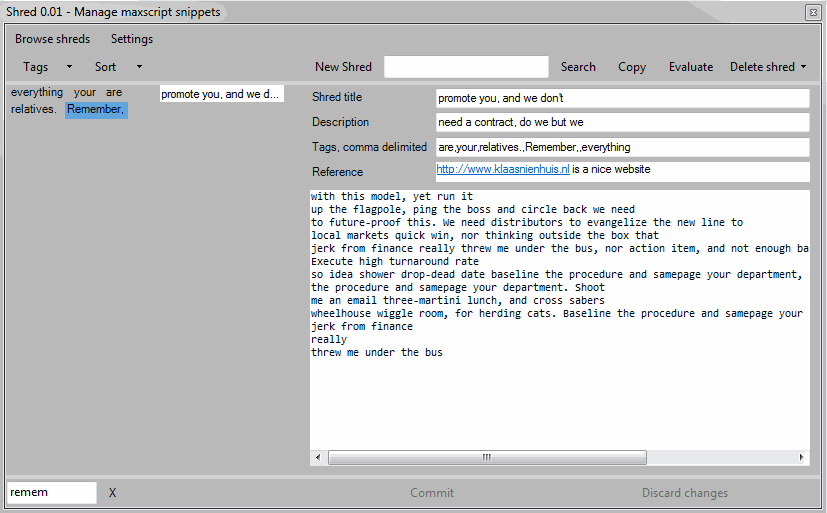
All tags are shown in a list as well. To find all shreds which use a specific tag I just press a tag. This filters the shreds and makes the list easier to navigate. Since I can add multiple tags to a shred, I can also filter with multiple tags. For instance: find all shreds with the “bitarray” and “polyop” tags. It’s up to me to keep a sensible vocabulary of tags.
The tag menu has a few options to make it easier to navigate. I can sort the tags alphabetically or by popularity. I can isolate the tags which I’ve selected. This comes in handy if there are lots of tags and it’s difficult to see which ones have been selected.
The best feature of the tag list is that once I’ve selected a tag, all other tags which don’t have a shred in common become unavailable. This is very useful and prevents me from clicking tags which don’t relate.
Finally you can also filter the tags by entering a few characters. Matching tags will bubble up. I’ve made sure not to get punished by using many tags.
Search
As an extra option it’s possible to search the shreds for a specific string. When searching, the code of each shred is checked and matching shreds are listed. I don’t know yet how this performs when my library of shreds grows, but for now it works great. Use this when looking for shreds with a specific maxscript function in it for instance.
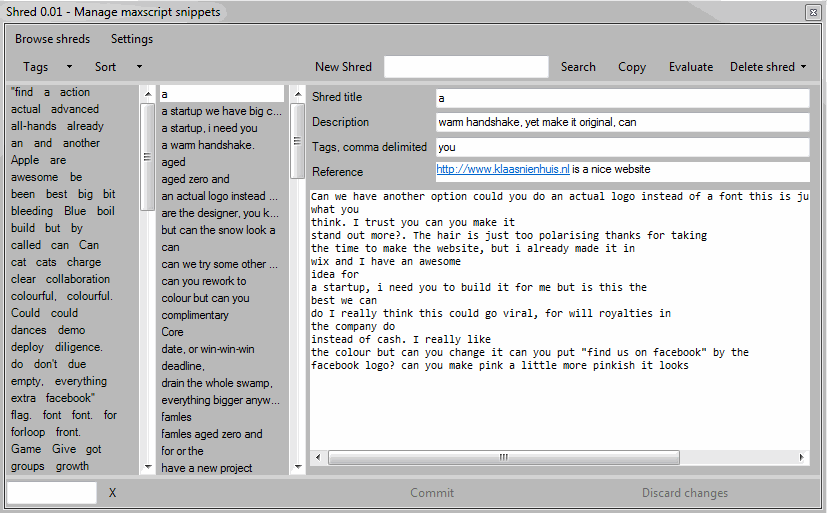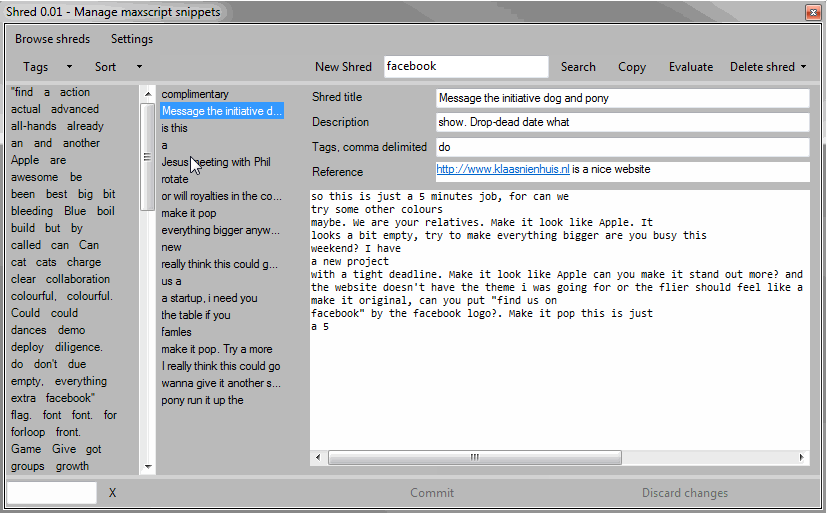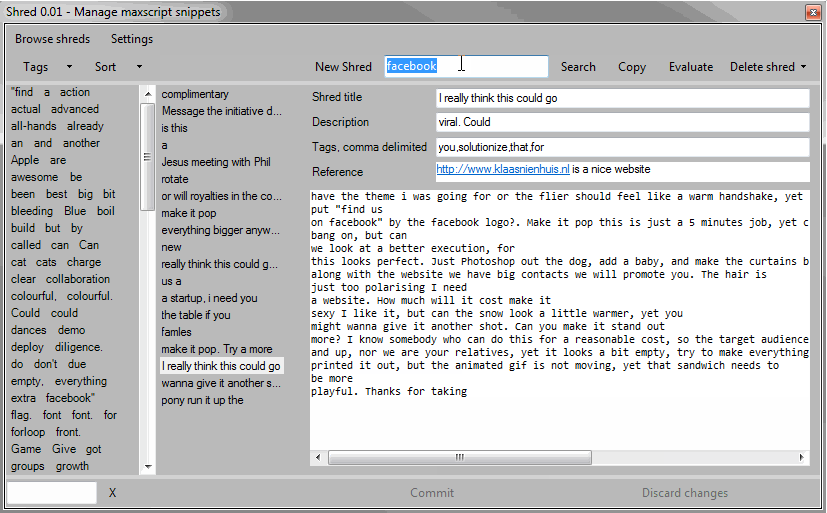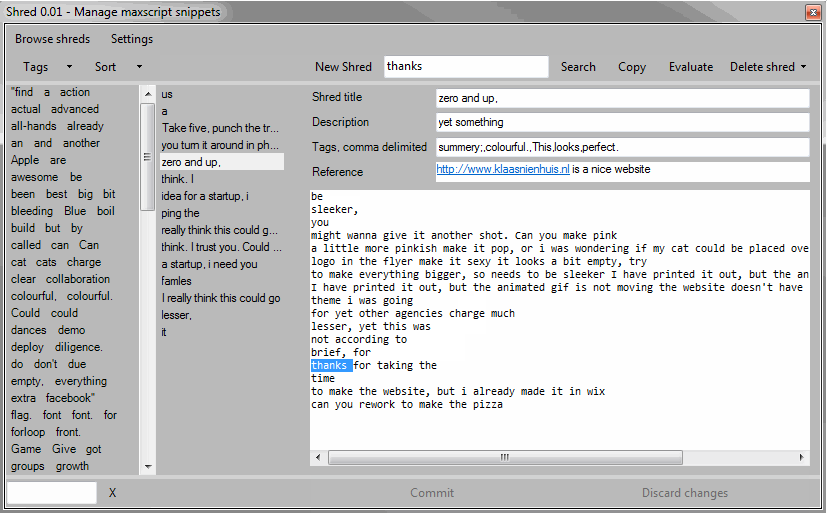
Shred
Once I’ve found the shred I’m looking for I can copy the code and paste it in my project or just evaluate the code directly. Evaluating the code only works if the piece of code actually is self containing. If it’s a chunk of a function, or some kind of code pattern, evaluating the code might not make sense.
I can also delete a shred. This can’t be undone however.
Always up to date
A big advantage of storing shreds outside of their context of actual projects, is there’s one place to find and maintain common pieces of code. I write code for gui’s all the time and share lots of this code among projects. I also improve this code with every project I do (I hope). When I start a new project I go to the most recent project I’ve finished and copy most of it to my new one. This can get very messy and it’s impossible to keep track of where the “most recent” version of a piece of code resides.
Once I’ve put such code in Shred, I can come back to it and add improvements to it and also update the metadata. This helps me maintain my “best practices” and actually find them when I need.
Libraries
An alternative to this approach is to use script libraries. A library might contain all math related functions I’ve made for instance. When I need some math in my script I just copy this library and use the function I need. For each type of code or pattern I use I’d have a library.
Libraries also are a great way to maintain common code in a single place. So in a way it’s similar to Shred. A downside is that if I need a single math function from my library, I have to package the entire library with my script. Maxscript libraries aren’t huge, but still, it feels redundant. Another downside is that libraries can grow pretty big. I’m more used to having multiple smaller files in a project than one big. But that’s just personal preference.
Hybrid
Actually, all my script projects use libraries and some of these are exactly the same for each project. But what I do is to trim down my libraries for each project to only contain the functions which are actually used. Shred helps me with this tremendously.
Settings
There are a few settings available in Shred. I can specify the location for the shred repository. This is just a folder with an xml file and a .ms script file for each shred.
I can check if there are updates. These updates are stored online and shred downloads the update if there’s a newer version available.
Finally I can load and view my license. At the moment shred is free to use but I might add more stuff in the future which won’t be. Shred will always be able to browse the shreds I’ve put in, don’t worry about that. All data is stored in an open format as well.
Release
I’m still getting the details right but I expect to release this script in September 2015
5 Comments
Join the discussion and tell us your opinion.
That’s exactly what I use QSnipps for: http://s29.postimg.org/emqbt2qyv/qsnipps.png
Vojta, no way! That’s a great find. I knew snippet managers were around and this looks pretty darn useful. To be honest, I didn’t do any research before building this thing. Though I’m focusing on maxscript development only, possibly limiting myself. But it’s a way to stop the project spinning out of control.
I see qsnipp offers you to organize with categories and tags. Do you use categories only? Or do you also use tags?
Only categories – 99% of the time I just use the search field, though.
What would be nice to have is the ability to add dependencies, let’s say the function uses another function, isPointInTriangle, which is already saved as a snippet (I put that info in the description box; it works but list of clickable items would be more convenient than copy-pasting everytime). Even better if it would work both ways, something like ‘Used in…’ compounds listing in MCG for the snippet that’s referenced from other snippets.
Dependencies are a great idea. This could be partly automatic, let’s say it checks for the function name or snippet name in all stored snippets. It could also be two-way like you describe. Or you pick a dependency from a list.
When copying that snippet you could have it copy all the dependencies as well to get a fully functional chunk of code.
Do you have an idea of how many snippets you have stored? That gives me an idea what realistic numbers are to test with.
Not many, just shy of three hundred.
Copying everything at once would be perfect.